Featured resource: Facebase
Posted by the Node, on 24 September 2025
Our ‘Featured resource’ series aims to shine a light on the resources that support our research – the unsung heroes of the science world. In this post, we learn about the data and functionalities available at Facebase, and hear about new initiatives they are developing.
What is FaceBase?
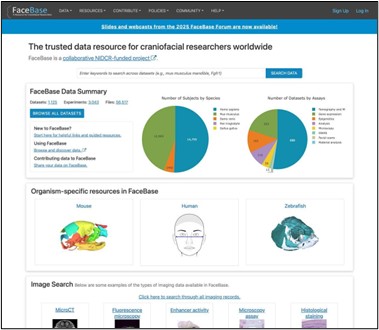
FaceBase is a public data resource and repository dedicated to advancing basic and clinical research spanning the translational spectrum of dental, oral, and craniofacial (DOC) biology, as well as related systemic health and disease models throughout the data lifecycle. FaceBase realizes this mission by recruiting, transforming, and publicly sharing research and clinical data.
This freely available and public resource currently hosts over 1,100 datasets, approximately 3,000 experiments, over 210,000 images, and more than 8,000 genomics files. FaceBase exemplifies FAIR (Findability, Accessibility, Interoperability and Reusability) and TRUST (Transparency, Responsibility, User focused, Sustainability, and Technology) principles of scientific data sharing, ensuring that its clean, well-structured datasets are not only easy to find and reuse, but are also inherently AI-ready for integration into modern computational workflows.
FaceBase hosts data from both human subjects and animal models, encompassing a wide array of experimental approaches, including multiple omics and imaging data types. This platform welcomes contributions of data from the community after going through a careful review process and quality assurance.
- 1,170 datasets, 2,984 experiments, 210,000+ images, 8,000+ genomics files
- Human subjects and animal model data (Current animal models include mouse, zebrafish, chimp and chick)
- Controlled-access and public data
- Genomic and phenotypic data from multiple species
- Most known types of genomics and imaging data
- Resources and strategies to enhance data reproducibility
- State-of-the-art data science methods to support cutting edge research
- Standards and educational resources for improving data management and sharing practices across the community
FaceBase demonstrated itself as a credible resource for the DOC research community through its CoreTrustSeal accreditation after a two-year approval process, as well as becoming one of a select number of NIH approved Controlled Access Data Repositories (CADRs) handling genomics and other sensitive data.
What inspired the development of FaceBase?
In 2009, National Institute of Dental and Craniofacial Research, National Institutes of Health (NIDCR, NIH) launched FaceBase in response to the need for more comprehensive analysis of craniofacial development. With the immense amount of craniofacial data being generated, there is a danger of relevant datasets being buried in the avalanche of genomic and other data.
The first five years (known as FaceBase 1) started with a spoke-and-hub of 10 spoke projects and resulted in almost 600 datasets and over 100 publications. The next phase of FaceBase (FaceBase 2) began in August 2014 with 10 spoke projects and a new hub that developed an updated data model allowing for more data integration and faceted searches with a new server interface. The third phase (FaceBase 3) dismantled the spoke-and-hub model in favor of a community-based model that opened submissions to any contributor. We also promoted the idea of self-curation which allowed us to scale up considerably: since opening up to community contributions, we have more than doubled the number of contributors and our dataset growth has kept pace with prior years.
How can scientists use FaceBase in their research?
For researchers and clinicians seeking to generate a hypothesis for a new grant, validate their own data by comparing with controls, or examine phenotypes in mutant models, the FaceBase Data Browser provides an intuitive interface. Data are represented as filtered records, with sidebar attributes that function similarly to filters on an online shopping site.
Find Data
You may begin your search with the BROWSE ALL DATASETS button on the homepage or you can use the DATA tab in the top navigation menu bar (available on all pages) to start with a particular model.
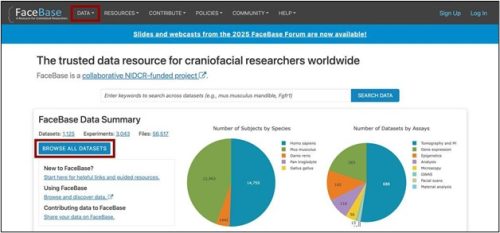
When you start searching the data browser you will see:
- Search results based on filters
- Faceted navigation sidebar on the left
- Search bar above the results
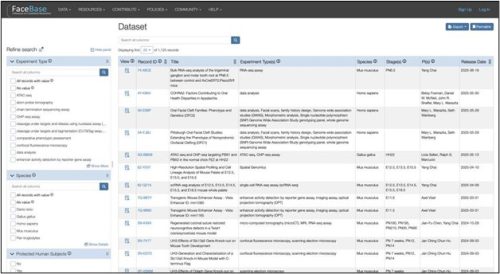
By default, the data is sorted to display the most recently released data first. On the left side is the faceted navigation based on characteristics of the data and experiments. Scroll down to see all the categories of filters available to narrow down your search.
Export Data
All open access data can be downloaded directly from the browser without requiring login. If you want to download a large amount of data, you can use our BDBag protocol-derived tool, which allows for reliable transfer of a “bag” of digital content – in this context, a group of files that you want to export in bulk. It is available as a GUI client and a command-line client.
For more information, see https://docs.facebase.org/docs/Exporting-Data-from-FaceBase/.
Fill out Data Management & Sharing (DMS) Plans
We also offer resources to help you include FaceBase in your Data Management Sharing (DMS) plan, including template text that you can copy and paste into your plan. You can find guidance on how to fill out the various fields here: https://www.facebase.org/contributing/dms/.
Who are the people behind the resource?
FaceBase is run by University of Southern California’s Center for Craniofacial Molecular Biology (CCMB) and Information Sciences Institute (ISI) in Los Angeles.
Our current leadership and staff include:
• Principal Investigators – Yang Chai (CCMB) and Carl Kesselman (ISI)
• Co-Investigators – Robert Schuler (ISI, technical lead) and Parish P. Sedghizadeh (Herman Ostrow School of Dentistry of USC)
• Scientific Curators – Jifan Feng, Tingwei Guo, and Thach Vu Ho (CCMB)
• Data Management Lead – Alejandro Bugacov (ISI)
• Collaborations and Communications Coordinator – Cris Williams (ISI)
• Project Manager – VyVy Nguyen (CCMB)
How can researchers help and contribute to the resource?
The most effective ways to support FaceBase are two pronged: 1) contribute data to improve the breadth and depth of our offerings and 2) cite any data you deposit or reuse by using the citation tools embedded in the platform.
Contribute data
FaceBase welcomes biomedical basic and clinical research across the translational spectrum related to the DOC domains as well as those from related systems. We are also an approved repository for the HEAL Initiative, an NIH-wide effort to speed scientific solutions to stem the national opioid public health crisis.
Our current funding phase expands our focus to accept research and data on relevant anatomical and biological health and disease models beyond DOC domains, for example the ear and eye or biomarkers that overlap with those found in DOC regions.
Interested researchers and clinicians simply fill out a short form (https://www.facebase.org/contributing/submitting/form.html) to submit their data for review.
After a review process from the FaceBase team and NIH program staff, approved projects will receive a one-hour one-to-one tutorial to learn how to curate their data using the online metadata forms and how to upload data. You can find more information about the process here: https://docs.facebase.org/docs/Data-Submission-Key-Concepts/.
Note that our focus is on high quality data that conforms to FAIR initiatives that bolster or expand existing data. Find more detailed descriptions of the types of data we are especially interested in here: https://www.facebase.org/contributing/data-priorities/. If you have any questions about whether your data is a good fit, please contact us at help@facebase.org.
Cite FaceBase data
FaceBase has been leading the charge on effective and transparent citation of data for many years. Every data record has its own unique, permanent identifier. In addition, every Dataset and Project page has a registered Digital Object Identifier (DOI) and a “Share and cite” button that provides citation text that you can simply copy and paste into your publication.
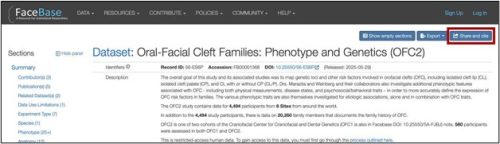

For more information and examples of citations, please go to: https://www.facebase.org/citing/
What are the next steps for FaceBase?
New collaborations and multi-tenant federation
EarBase: As part of our new focus to include research and data from relevant anatomical and biological health and disease models, FaceBase is collaborating with the National Institute on Deafness and Other Communication Disorders (NIDCD) to migrate 3D images of the temporal bone that were previously held in a private enclave.
CranioRate: Another new development is our collaboration with CranioRate, a user interface that is being launched in late 2025 to help surgeons and clinicians manage metopic craniosynostosis cases, a birth defect that affects the structure of the skull. In particular, FaceBase is supporting their open access human craniosynostosis image bank and working towards standardized vocabularies and ontologies to ensure the data’s FAIR-ness.
Integrating clinical elements from Electronic Health Records (EHR)
We are collaborating with clinician-scientists on a pilot project to integrate clinical data from patients with temporomandibular disorders (TMD) into FaceBase. Important directives of this pilot include ensuring clear patient consent for repository use (that specifically permit the use of identifiable health information for research without requiring re-authorization) and exploring the potential of AI/ML methods to analyze clinical notes and improve diagnostic accuracy.
Advanced computation and AI-ready analytics
By definition, aligning the data in the FaceBase repository with FAIR principles means that our data, which is clean, well-formatted, with structured metadata and provenance, is ready for a data scientist to pull into analytics platforms. In the future, we plan to continue to enhance the AI-readiness of our data, provide curated collections of “reference datasets” for training purposes, and enable interoperability with LLMs and lab notebooks and develop an AI-assisted curation bot for data contributors.
Interoperability with external data resources
We are also developing a pipeline to transform raw FaceBase data into a processed format that can be ingested by external resources, for example a cloud-based analytics platform.
Where can we find FaceBase?
You can find us at www.facebase.org and you can always contact us at help@facebase.org.
Other ways to connect:
- Attend one of our monthly Office Hours on the last Wednesday of each month via Zoom (requires registration).
- Join our mailing list by signing up for a FaceBase Users account.
- Follow us on Bluesky or X.
 (No Ratings Yet)
(No Ratings Yet)Get involved
Create an account or log in to post your story on the Node.
Sign up for emails
Subscribe to our mailing lists.