Preprints: biomedical science publication in the era of twitter and facebook
Posted by Katherine Brown, on 27 October 2016
Earlier this week, I took part in a workshop on preprints – organised by Alfonso Martinez-Arias and held in Cambridge, UK. Inspired by the ASAPbio movement in the States, Alfonso felt it would be useful to bring discussion of the potential value of preprints more to the forefront in the UK. Happily, he was able to get John Inglis, co-founder of bioRxiv (the primary preprint server for the life sciences), to speak at this event, and also invited several other speakers – including myself – to talk about their experiences with preprint servers.
If you’re interested, the whole event was live-streamed, and you can watch the video here. But for those (understandably!) not wanting to spend 3 hours listening to people talk about preprints, here’s a (not-so-brief) summary. Or check out #pptsCamOA for the live tweeting.
If you’re not familiar with bioRxiv or preprints more generally, I’d definitely encourage you to watch John’s talk at the beginning of the video (starting around 7 minutes) – he gave a great overview of the history of bioRxiv and its potential future. One thing I find interesting is why it appears that bioRxiv is succeeding while previous efforts – most notably Nature Precedings – failed (see graph below). Presumably this is primarily because bioRxiv got its timing right: we’re in a period of changing culture with respect to science publishing, and bioRxiv is riding a wave of discontent with traditional publishing systems. Perhaps Nature Precedings just came too early, but perhaps also people have been more willing to rally behind a not-for-profit enterprise not directly linked with a publishing house (bioRxiv is supported by Cold Spring Harbor Labs not by the Press).
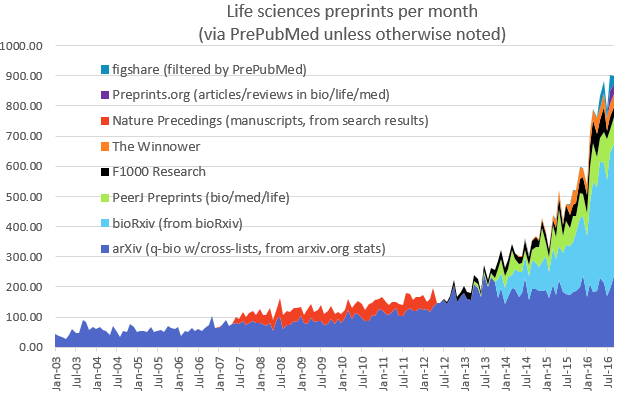
Image from http://asapbio.org/preprint-info/biology-preprints-over-time
Credit: Jessica Polka
As you can see from the graph, bioRxiv is expanding rapidly (now with around 450 deposits and over 1 million article accesses per month), and it’s clear to me that preprints are here to stay – though there are still a number of important challenges to address (check out the video from around 32 minutes to see where bioRxiv is going).
That preprints are becoming increasingly mainstream is also reflected in the fact that most journals are now happy to consider papers that have been posted on preprint servers – including Cell Press, who were initially and somewhat notoriously reluctant to make a clear statement on that front. Two representatives from the publishing industry talked about their attitudes to preprints – me (representing Development and The Company of Biologists) and Mark Patterson from eLife. Mark identified three reasons why eLife supports preprints: that ‘journals shouldn’t get in the way’ of what scientists want to do, that ‘journals and preprints complement each other’ and, somewhat enigmatically, that ‘new possibilities arise’. Here, Mark introduced the audience to a concept that most of the audience (myself included!) weren’t familiar with – a preprint-overlay journal. Exemplified by the maths journal Discrete Analysis, the idea here is that the journal is built on top of the preprint server, with the server (in this case arXiv) hosting the content, and the journal providing the peer review element. Later on in the workshop, Aylwyn Scally returned to this idea as his vision for how academic publishing might work in future, and it’s certainly an interesting idea…
Unlike eLife and its somewhat revolutionary ethos, The Company of Biologists is a much older and more traditional publishing enterprise, and it has taken us some time to embrace preprint servers, with each journal changing policy at different times according to feedback from its community – as shown in the excerpt from one of my slides below (I make an appearance at 56 minutes on the video). While it’s only recently that all our journals have supported preprint deposition, we’re now fully on board, and will shortly be fully integrated with bioRxiv for simple bidirectional transfer between journal and preprint server.
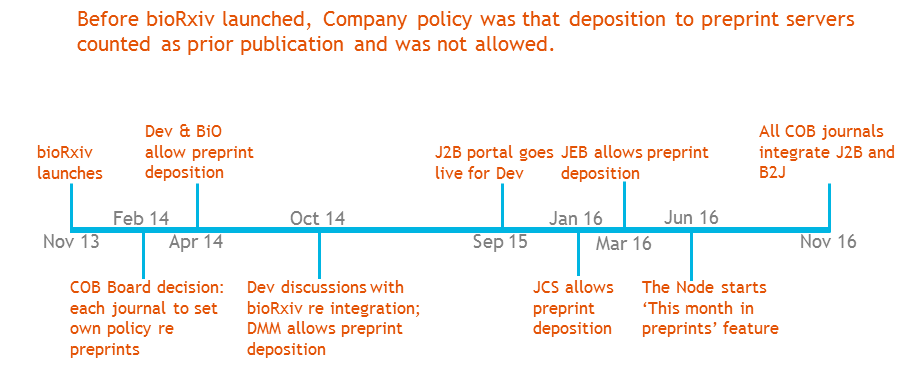 J2B portal is the system allowing simple transfer from the journal submission site to bioRxiv for immediate posting; B2J is the reverse portal whereby authors uploading a file to bioRxiv can easily submit to an integrated journal.
J2B portal is the system allowing simple transfer from the journal submission site to bioRxiv for immediate posting; B2J is the reverse portal whereby authors uploading a file to bioRxiv can easily submit to an integrated journal.
The final speaker for the first session was Hannah Hope from the Wellcome Trust. Given that preprints allow you to get your research out to the community earlier, but that that research is not yet peer-reviewed, funding agencies have to decide whether or not to ‘count’ preprints when assessing someone’s productivity for grant or fellowship applications. The Wellcome Trust has taken a forward-looking approach to this and supports the use of preprints in applications and end-of-grant review. They’re also working with other funders to develop a common set of principles – which should be made public soon. This is great news for researchers who need to apply for a grant before their paper is formally published but who want to demonstrate that they have a good track record in their field, and hopefully will become common practice among funders!
In addition to hearing the voices of publishers and funders, Alfonso had invited several preprint users to talk about their experiences. Raymond Goldstein, an interdisciplinary PI whose work spans the physics-biology divide (and includes IgNobel prize winning work on the shape of a ponytail!), gave us the viewpoint of someone for whom posting on arXiv has been common practice for decades and for whom the surrounding angst that many biologists feel is alien. He pointed out that, with LaTeX-based formatting tools, one can generate a beautifully formatted version of the manuscript to submit to a preprint server – common practice in the physical sciences, but with most biologists still married to Microsoft Word, isn’t something we’re yet comfortable with. Raymond also raised an important question about discoverability of preprints and argued that it might make more sense to have a central server to hold everything in one place, rather than multiple outlets for preprints.
Steve Royle told us ‘how and why I became a preprinter’ – explaining that his frustration with the amount of time it takes to get a paper published (see his blog post for some fascinating stats on this – it can be quicker to produce a baby than a paper!) induced him to start depositing preprints. As paraphrased by Richard Sever on twitter, Steve said that ‘preprints bring the joy back during the soul-destroying wait for journal publication’. Aylwyn Scally highlighted his concerns about how the peer review system works (what credit do referees get for the work they put in?) and how he feels preprints can help change the system. Sudhakaran Prabakaran‘s unusual career path – spending time as an editor at AAAS before returning to academia to set up his own lab – has given him a unique viewpoint on academic publishing. His main point was that review takes too long (mainly because reviewers take too long!), and that preprints therefore provide a possibility to get your work out more quickly, and to take advantage of altmetrics to get your work known in the community. Finally, Brian Hendrich took to the stage to explain why he felt compelled to post a preprint to alert readers to potential problems with a published paper (something that Steve Royle also mentioned), and why he then didn’t feel the need to get that preprint formally published elsewhere.
In addition to the talks, there was a lot of discussion surrounding why preprints are useful and where we are going with them. It was great to hear some of the early career scientists express their opinions – mainly but not exclusively positive – about preprints. One expressed concern about putting her work out on a preprint server without the ‘sanity check’ of peer review, while another explained how he felt his preprint helped him get his Henry Dale Fellowship. Discussion also centred around the degree to which preprint posting can claim precedence for an idea or a set of data (though without firm conclusion!), and to what extent peer review can claim to ‘validate’ a scientific paper. In general, I found it a hugely constructive discussion, and I came away feeling positive about how preprints and journals do and can integrate to allow researchers to better disseminate their research.
At the end of my talk, I posed a bunch of questions that I hoped would provoke discussion among the audience, and I’d also be really interested to hear people’s feedback here, so please feel free to comment on any of these below!
- When should authors ideally submit to preprint server?
- Should editors be searching through preprint servers and soliciting potential submissions?
- What do preprints mean for precedent and scooping? Will researchers claim precedence through deposition of very preliminary data?
- How might this impact on e.g. data/materials sharing or patent applications?
- Is there a danger of making un-reviewed data publicly available – especially medically relevant/translational research?
- Might commenting on preprints complement or even replace traditional peer review and what would it take to make this happen?
- Is it good that we have one dominant preprint server for the life sciences or should there be several?
 (9 votes)
(9 votes)6 thoughts on “Preprints: biomedical science publication in the era of twitter and facebook”
Leave a Reply
Get involved
Create an account or log in to post your story on the Node.
Sign up for emails
Subscribe to our mailing lists.
Great write up Katherine. I thought I would comment here since I was saying that feedback is very important. The questions that you posed are all points for long discussion. My 2p on the first two questions:
– Ideally, I think authors should preprint and wait a week or so to collate feedback and then submit to a journal. In practice though simultaneous submission makes most sense. Preprinting after submission doesn’t make sense to me, but maybe authors can have a change of heart!
– They definitely should! I have written about this here:
https://quantixed.wordpress.com/2016/05/26/voice-your-opinion-editors-shopping-for-preprints-is-the-future/
For our last preprint we had an offer from a journal. It’s flattering (we’d already sent it somewhere else), but I can see circumstances where you put something up and see which journal is interested.
Thank you for this post. Following Steve’s example, here are answers to your questions (and for those interested in the event, here is the ‘curated version’ from the ASAPbio site: http://asapbio.org/event/preprints-biomedical-science-publication-in-the-era-of-twitter-facebook ; by the way, take a look at the ASAPbio and the work they are doing). But, onto the task
1) When should authors ideally submit to preprint server?
I agree with Steve’s that it would be good to post first and wait for comments but it is also true that our ability to comment is not great. One hears stories of feedback through email (I have done that) but we are still not very conversant. A few months ago, we decided to put a working version of a manuscript and results in bioRxiv (http://biorxiv.org/content/early/2016/05/13/051722), we are still transforming it into mss for peerreview but, in the meantime we have received feedback and even a generous reference (http://www.sciencedirect.com/science/article/pii/S095506741630151X).
2) Should editors be searching through preprint servers and soliciting potential submissions?
This is up to the journals. In some ways they do that when they go to meetings. Using preprints as a source of information is much better as the evidence is laid down in detail rather than in the context of the hype of the talk. As we discussed at the event, this will evolve and meta-journals will arise from the preprint culture. Journals should move fast or else they will be left behind.
3) What do preprints mean for precedent and scooping? Will researchers claim precedence through deposition of very preliminary data?
I think people should read Ginsparg on this and more (http://onlinelibrary.wiley.com/doi/10.15252/embj.201695531/epdf). Biologist have strange concepts of simple things. My simple answer to this question is like a physicist: of course! A longer answer, shortly.
4) How might this impact on e.g. data/materials sharing or patent applications?
What works for the physicists, should work for us. It’ll be interesting to see what their culture is on this.
5) Is there a danger of making un-reviewed data publicly available – especially medically relevant/translational research?
It seems to me that information on peerrviewed journals has its problems too (many examples). So, until proven wrong, I don’t see a reason to worry more about this with preprints and peerreviewed journals. On this, also, it is important that people know (and John Inglis explained it very well at the event) that preprints in bioRxiv have passed two filters, which are designed to protect the community from exactly this.
6) Might commenting on preprints complement or even replace traditional peer review and what would it take to make this happen?
Yes and no. This would take a longer answer. Biology is a strange field (see Ginsparg above)
7) Is it good that we have one dominant preprint server for the life sciences or should there be several?
It is inevitable that there will be many and that people will choose. But I prefer one or a few. Maybe the ‘many’ version could be arranged by topics, but I am not happy with an explosion (some associated with commercial purposes)
Hope this is helpful. I also encourage people to look at ASAPbio. In particular their survey on preprints http://asapbio.org/survey
Great summary, Katherine.
When should authors ideally submit to preprint server?
When the work is solid and the point proven.
One of the issues we’re fighting is with over-publication – the idea that everyone has to publish every year and it has to be impactful. That pressure makes people tell lies. Preprint servers are wonderful but not tools for increasing the already bokers publication rate.
Should editors be searching through preprint servers and soliciting potential submissions?
Whyever not? Anything that helps scientists spread good science to the best selection of readers is great. Only one worry – editors have to retain objectiveness in the face of peer review.
What do preprints mean for precedent and scooping? Will researchers claim precedence through deposition of very preliminary data?
They may try; we must be ready for it (and see my 1st answer). One of the things we ought to do is instil a sense of shame and a payback for selling incompletely justified work. Needs keeping in mind, it’s a good and important point.
How might this impact on e.g. data/materials sharing or patent applications?
Dunno. Needs to be answered by an expert.
Is there a danger of making un-reviewed data publicly available – especially medically relevant/translational research?
We (the field) have to work very hard to maintain the difference, and to harrass journalists and press offices that fail to. This is very important indeed.
Might commenting on preprints complement or even replace traditional peer review and what would it take to make this happen?
In a sense I wish it would, because over my career the quality of peer review has gone down appallingly, but it remains the same sacred red line in career and publishing terms. I wish that peoples’ career prospects depended on the quality of comments they’d made to lots of papers in the field, and that granting agencies would take a look to see if the people they were funding understood what they were talking about. Not commenting would not be a negative – but might end up a competitive handicap if others were showing insight. Which is fine.
Is it good that we have one dominant preprint server for the life sciences or should there be several?
Doesn’t matter. Arxiv is fine for physics. Having several woul be fine too.
Point 4 (How might this impact on e.g. data/materials sharing or patent applications?) is rarely addressed. I can comment on one specific case – plasmids. In my opinion the sequences of plasmids, or, preferably, the plasmids themselves should be made available directly upon posting a preprint.
There is no policy at this moment for sharing of materials, and enforcing such release of material will be difficult (or impossible). Still, we should urge scientists to share materials….
Thank you very much for your summary of what sounds like a very interesting event. Here are some thoughts on your questions:
When should authors ideally submit to preprint server?
This should be up to the authors. We posted our preprints at the same time as submitting to a regular journal. It was the time point we felt our work was ready for sharing. Posting the preprint before journal submission could in theory be a good way to solicit feedback, improve the manuscript and then submit an improved story with a higher chance to be accepted. But in reality the amount of feedback that one typically receives is not worth the wait. And it is not like one could not incorporate feedback while the manuscript is at the journal. The revisions for all our manuscripts that were on Biorxiv have been influenced by feedback we received by email. For example, this summer I received an email from somebody who had read our preprint and spotted a small mistake in one of the figures. The paper had already been accepted without anyone noticing the mistake, but due to this email I was able to contact the journal and have the figure corrected before it was published. This is just a small example how feedback on preprints can be very helpful at any stage of the publication process.
Should editors be searching through preprint servers and soliciting potential submissions?
Sure, why not? The journal must decide whether it is worth the effort. My guess is that most authors have already sent their paper somewhere. But they might be looking for an alternative venue soon, so an email indicating interest in the manuscript could be helpful.
What do preprints mean for precedent and scooping? Will researchers claim precedence through deposition of very preliminary data?
In biology we are far too obsessed with priority. We should establish a system where reward goes to whoever gets it right, not whoever gets it first. If that were the case, there would be no incentive to post a study that is not yet solid. You would get scooped by someone who has a better, more complete story – no matter when that is published. But preprints that report solid science should indeed establish priority. It would be silly to ignore their presence. The whole world can read them – which can’t be said about most journal articles.
Is there a danger of making un-reviewed data publicly available – especially medically relevant/translational research?
No, I don’t think so. I think it is unhealthy to pretend that the fact that a study appears in a peer reviewed journal means it is correct. We all know that there are plenty of journals that are supposedly peer reviewed, but will publish anything for money. And nobody will have to think long to come up with multiple examples of exaggerated or falsified studies that have appeared in the most glamorous journals. There is good and there is bad science and we should work as a community to establish and communicate, which studies belong to what category. Preprint servers can make an important contribution to that. They are tools for more, not less, peer review. They aim to democratise the assessment of science, so we get away from a system that relies on the judgement of usually only two to four people. Importantly, peer review on preprint servers would happen in the open, allowing scientists, journalists and the public to take into account the various points of view.
Besides, Biorxiv clearly states on every preprint that it has not been peer reviewed and most people will understand what that means.
Might commenting on preprints complement or even replace traditional peer review and what would it take to make this happen?
See above. It would be great for science if preprints would spark more peer review and would give a platform for other voices to be heard. In reality, this is not happening so far. The lack of time and the fear of alienating colleagues keeps most people from posting open reviews on preprint servers. This could change if there were real incentives to do so. For example, funders could give applicants the opportunity to highlight open reviews in fellowship and grant applications and thoughtful reviews could play a factor in such decisions. This should not only apply to the review of preprints, but for example also to post-publication peer review on platforms such as PubMed Commons.
Is it good that we have one dominant preprint server for the life sciences or should there be several?
It does not matter, as long as there are good search engines.