We seek an outstanding postdoctoral candidate to join the Perry lab at the University of California, San Diego. Our group uses genetic and genomic approaches to study the development and evolution of neural systems. We use the insect visual system as a model to understand how the genome encodes the complexity of the brain and nervous system. We are interested in the mechanisms that generate the exquisite diversity of ways in which animals perceive and interact with the world.
We are specifically seeking independent, passionate, and highly motivated applicants for a postdoctoral position to study the evolution and development of butterfly color vision, with a focus on understanding the specific genetic changes that produce a more complex retinal mosaic. Butterflies have doubled the number of R7 photoreceptors in their retinas, allowing for an increased number of color comparisons (see Perry et al. Nature 2016). We use CRISPR to test gene function directly in developing butterfly retinas. A second part of this project will be aimed at understanding how the brain interprets this additional input and the role of developmental plasticity. A portion of the work will involve using sophisticated genetic tools in Drosophila to understand relevant circuits. A Ph.D. in the biological sciences with at least three years of laboratory research experience in molecular or developmental biology is required. Experience with Drosophila or other genetic model systems is preferred but not required.
This is a renewable two-year position with full benefits, which will be extended as needed upon good performance of the candidate. Salary will be competitive and dependent on the level of experience of the candidate. Applicants should email a CV and a description of research interests to Prof. Perry (mwperry@ucsd.edu), along with contact information for three references. Applications submitted by November 1st, 2020 will receive priority consideration, but the position will remain open until filled. Start date is flexible.
It is an incredibly exciting time to be a developmental biologist as new tools such as CRISPR and single cell sequencing allow us to move beyond model systems in order to ask targeted questions about the mechanisms that adapt animals to their unique environments. Apply and join the adventure!
Note: this is a reposting for a search that was cancelled due to COVID.
We are seeking to recruit a new member to our team at the University of Cambridge to contribute to the FlyBase Drosophila database (https://flybase.org).
A large and growing community of Drosophila biologists is producing single cell transcriptomic data with potentially high value to the research community. This includes both individual labs and also large-scale community efforts focussed on sharing and annotating single cell RNA sequencing (scRNA-seq) datasets covering the whole fly, such as Fly Cell Atlas (https://flycellatlas.org/).
The Graduate School Life Science Munich (LSM) offers an international doctoral programme to motivated and academically qualified next generation researchers at one of Europe’s top Universities. LSM members are internationally recognized for their innovative research approaches and technologies, they are aiming to answer essential questions relevant to basic and applied biological and biochemical research. Within their own research group or in collaboration with a specialized research group on campus, LSM doctorates are given the opportunity to learn and command a variety of techniques. Furthermore, the graduate programme holds various workshops and seminars that strengthen and prepare doctorates for a successful career as scientists.
With over 40 research groups from the Faculty of Biology and the Faculty of Chemistry and Pharmacy of Ludwig Maximilian University (LMU) München, the LSM in its prominent location within the HighTechCampus in Martinsried south of Munich, contributes to the enormous possibilities for support, interdisciplinarity and constant scientific input from the surrounding laboratories. Available research projects cover areas from Cell and Developmental Biology, Epigenetics, Genetics, Microbiology, Molecular Biology, Biochemistry, Evolutionary Biology, Plant Sciences, Pharmacology, and Systematics. https://www.lsm.bio.lmu.de/faculty/index.html
LSM calls for doctoral applications on a yearly basis, open from the 1st of October until the 30th of November 2020. Applicants are selected in a multi-step process through our online portal, thus ensuring openness and fairness throughout the application procedure. Every complete submission is evaluated by the LSM coordinator. Applications will be independently reviewed by several faculty members of the LSM Graduate School. Based on academic qualification, research experience, motivation, scientific background and the letters of recommendation, candidates will be selected to participate in the LSM Interview week. After thorough evaluation through the LSM committee board members, successful candidates will be invited to join the LSM Graduate School. Further information and details about the online application process and the available funded research projects can be found here: https://www.lsm.bio.lmu.de/apply/index.html
Additionally, the DAAD and LSM jointly award 2 full scholarships for doctoral study financed by the DAAD Graduate School Scholarship Programme (GSSP). Further information and details about the online application process and the available DAAD scholarships can be found here: https://www.lsm.bio.lmu.de/daad-lsm-application/index.html
We’ve had over 400 registrations already! For those attending, this post has been updated with an order of play for the day, and the webinar homepage has also been updated with a How To for Remo, our browser-based conference software – no download needed!
Development presents… is a new webinar series showcasing the latest developmental biology and stem cell research. The webinars are chaired each month by a different Development Editor, who invites talks from authors of exciting new papers and preprints. First authors are particularly encouraged to present their work – we hope the series will become a forum for supporting early career researchers. As well as presentations and live Q&A sessions, you’ll also get the chance to meet the speakers and fellow participants at interactive virtual tables. For dates and details of future events once confirmed, why not bookmark thenode.biologists.com/devpres
The first webinar of the series will take place on Wednesday 7 October at 16:00 BST and be chaired by Development’s Editor-in-Chief, James Briscoe (Group Leader at the Francis Crick Institute in London), who has has brought together three exciting talks.
Webinar schedule (all times in GMT+1)
15:55
Remo conference centre opens (accessible via a link sent out on the day to registered participants).
A postdoctoral position (fully-funded for 4 years) is available in the laboratory of Dr. Rashmi Priya at the Francis Crick institute. Dr Priya’s laboratory focuses on the mechano-molecular control of organ development during embryogenesis. For a brief overview of the lab, please visit https://www.crick.ac.uk/research/labs/rashmi-priya or get in touch with Dr. Priya.
The Organ Morphodynamics lab is starting at the Francis Crick in January 2021 and will grow to six people over the next 2 years. We have generous core-funding support and access to state-of-the-art facilities and technology platforms including Advanced light microscopy, High throughput sequencing, Bioinformatics and Image analysis help desk. The Francis Crick is a modern, world class biomedical research institute in central London. The Francis Crick and the participating organizations (UCL, Imperial College London and King’s College London) offer a highly inclusive, collaborative and thriving research community with many career development opportunities.
I am especially looking for candidates who are interested in combining interdisciplinary approaches to gain a systemic understanding of organ morphogenesis using a well-suited model system – the developing zebrafish heart. The project will aim to unravel the underlying mechanical, molecular and geometric interactions that transforms a developing heart from a simple epithelium into a highly intricate patterned organ.
The suitable candidate will use advanced microscopic techniques, image analysis, genetic/optical manipulations, biophysical approaches and collaborate with theoreticians to understand how morphological and molecular complexity emerges during heart development. Candidates with a strong background in advanced confocal and/or light sheet imaging, image analysis, zebrafish genetics and a good understanding of the mechanics of tissue morphogenesis and/or heart development are encouraged to apply. The successful candidate should be keen in pursuing collaborative research, should have excellent communication skills and should be a good team player.
For further details about the project and how to apply, please visit the Crick vacancies portal or get in touch – rashmi.priya@crick.ac.uk.
The cytoskeletal filament network within our cells underpins the functionality of virtually all cellular processes. Apart from conferring a structural framework giving cells their unique shapes, the cytoskeleton also regulates a host of dynamic activities ranging from cell division to migration, transport, and polarization. Understanding how the cytoskeleton orchestrates these events with unique spatial and temporal specificity within a developing organism remains one of the most fascinating questions in the field.
During the earliest stages of mammalian life, the cytoskeleton guides the formation of the blastocyst – a cluster of 32- to 64-cells comprising a differentiated outer cell layer known as the trophectoderm that will give rise to placental tissues, and a pluripotent inner cell mass that later forms the foetus itself (White et al., 2018). The early mouse embryo contains all three major cytoskeletal filament classes: actin, microtubules, and intermediate filaments. Interestingly, while many studies have investigated the roles of actin and microtubule filaments in regulating early embryo development, the function of the intermediate filament network during this time has remained entirely unknown. Yet unlike their more well-studied counterparts, intermediate filaments encompass a diverse range of proteins including keratin, vimentin, and desmin that are expressed in unique tissue-specific patterns, and can self-assemble into filaments in the absence of cofactors or nucleators.
We initially approached this question by consulting the literature: in 1980, the first papers were published identifying keratins as the first and only cytoplasmic intermediate filaments expressed in the early mouse embryo (Jackson et al.,1980; Paulin et al., 1980). Although there are over 50 keratin subtypes, the predominant ones in the early embryo are K8 and K18, the same subtypes that are characteristic of simple epithelia in mature tissues. A number of studies subsequently investigated keratin expression patterns during these early developmental stages, establishing their restricted localization in trophectoderm cells of the blastocyst and complete absence within the inner cell mass (Chisholm and Houliston, 1987; Duprey et al., 1985; Oshima et al., 1983). Yet their expression prior to blastocyst formation was never firmly established, owing to conflicting findings and differing methodologies. Combined with the fact that keratin knockout embryos survived preimplantation development (Baribault et al., 1993, 1994; Magin et al., 1998) and that the few early studies perturbing keratin functions reported no significant embryo phenotypes (Emerson, 1988), interest in keratin filaments during early embryo development gradually waned around the turn of the millennium.
Relooking at keratin filaments in the early mouse embryo almost three decades later offered us surprising insights. Although keratins are most well-known for their structural role in hair, skin, and nails, more recent studies have found that keratins within epithelial tissues also have diverse non-structural roles, including cell polarization, apoptosis, and cell cycle regulation (Kirfel et al., 2003; Pan et al., 2013). Armed with this knowledge and the foundation laid by earlier studies, we thus explored whether keratins in the early embryo – with their unique expression pattern in the outer epithelial layer (trophectoderm) of the blastocyst – could play specific structural or non-structural roles during embryo development like other epithelial keratins.
To investigate keratin functions, we established a combination of immunofluorescence and live-embryo imaging techniques that enabled us to explore keratin patterns with high spatial resolution and evaluate their dynamic changes during development. Apart from these technical improvements offered by newer microscopy tools, we also went beyond the early keratin studies by establishing knockdown and overexpression methods to manipulate keratin filaments within the living embryo, providing a valuable model for assessing keratin functions.
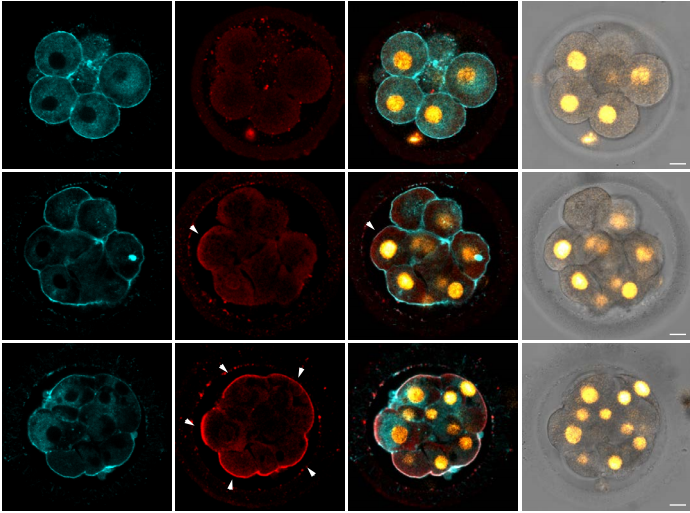
In our paper, we report some of the first functions for keratin filaments in the early mouse embryo. We find that keratin filaments act as asymmetrically inherited fate determinants that specify the first trophectoderm cells of the early embryo. Unlike actin and microtubule filaments that dramatically reorganize during cell division, keratins are stably retained within the apical region of the mitotic cell, during the first divisions that segregate cells into inner and outer positions at the 8- to 16-cell stage (Fig. 1). This apical retention of keratins biases their asymmetric inheritance by the outer forming daughter cell (Fig. 2). Apical keratin localization is further mediated by the F-actin-rich apical domain,without which keratin filaments become homogenously distributed throughout the cell, and no longer segregate unequally between the forming daughter cells. This underscores the importance of keratin-actin interactions in guiding keratin filament dynamics and functions during embryonic development.
Fig. 1. Keratin filaments (labelled by K8 immunofluorescence) are stably retained in both interphase and mitotic cells of the embryo. In contrast, both the apical enrichment of actin (labelled by Phalloidin-Rhodamine) and the microtubule network (labelled by alpha-tubulin immunofluorescence) throughout the cytoplasm are lost when cells enter mitosis.
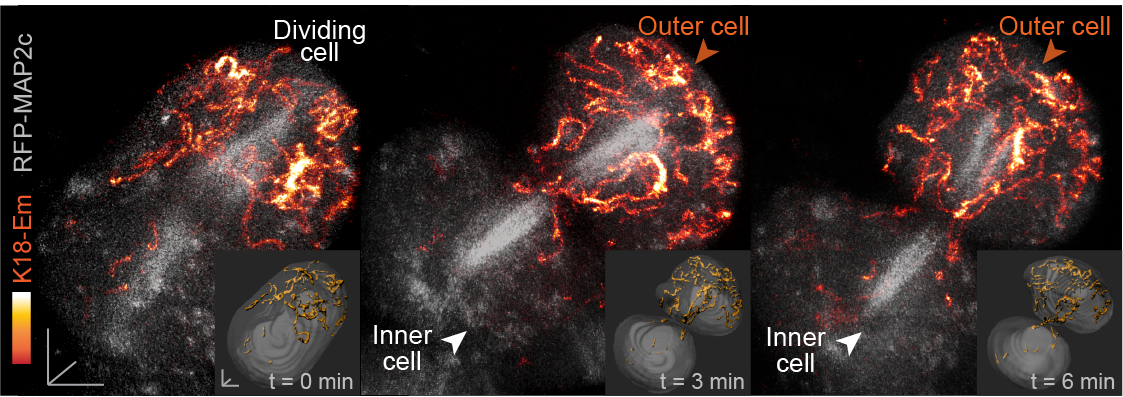
Fig. 2. Live embryo imaging reveals that keratin filaments (labelled by K18-Emerald) are asymmetrically inherited by outer daughter cells, during the cell divisions segregating inner and outer cells of the embryo.
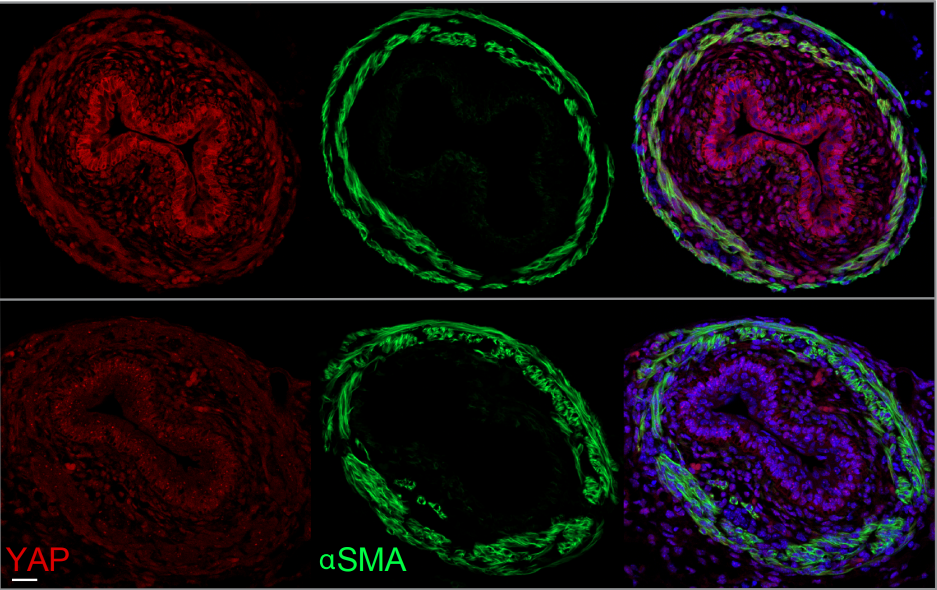
How do keratins go on to function as fate determinants? Following their asymmetric inheritance by outer cells of the embryo, we find that keratins promote apical polarization and levels of downstream members of the Hippo pathway including Amot and nuclear Yap. This in turn drives the expression of Cdx2, one of the key transcription factors specifying trophectoderm fate in the early embryo. Conversely, outer cells that did not inherit keratin filaments or those with keratin knockdown fail to establish these trophectoderm features, instead displaying levels of Cdx2 comparable to inner cells of the embryo.
At later stages, in line with the established role of keratins in conferring structural support to epithelial tissues, the dense keratin network in the trophectoderm is also important for supporting blastocyst morphogenesis. Keratin knockdown reveals that without this filamentous network, embryos display defective apical and junctional morphologies suggestive of weakened tension, as well as reduced cellular stiffness. Thus, keratins in the embryo regulate both morphogenesis and fate specification to promote blastocyst formation and the specification of the first cell lineages in development.
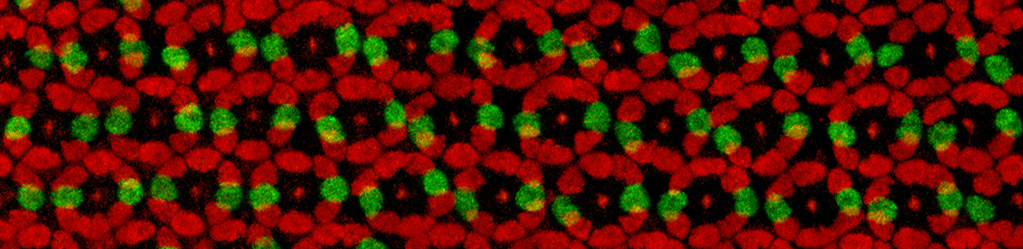
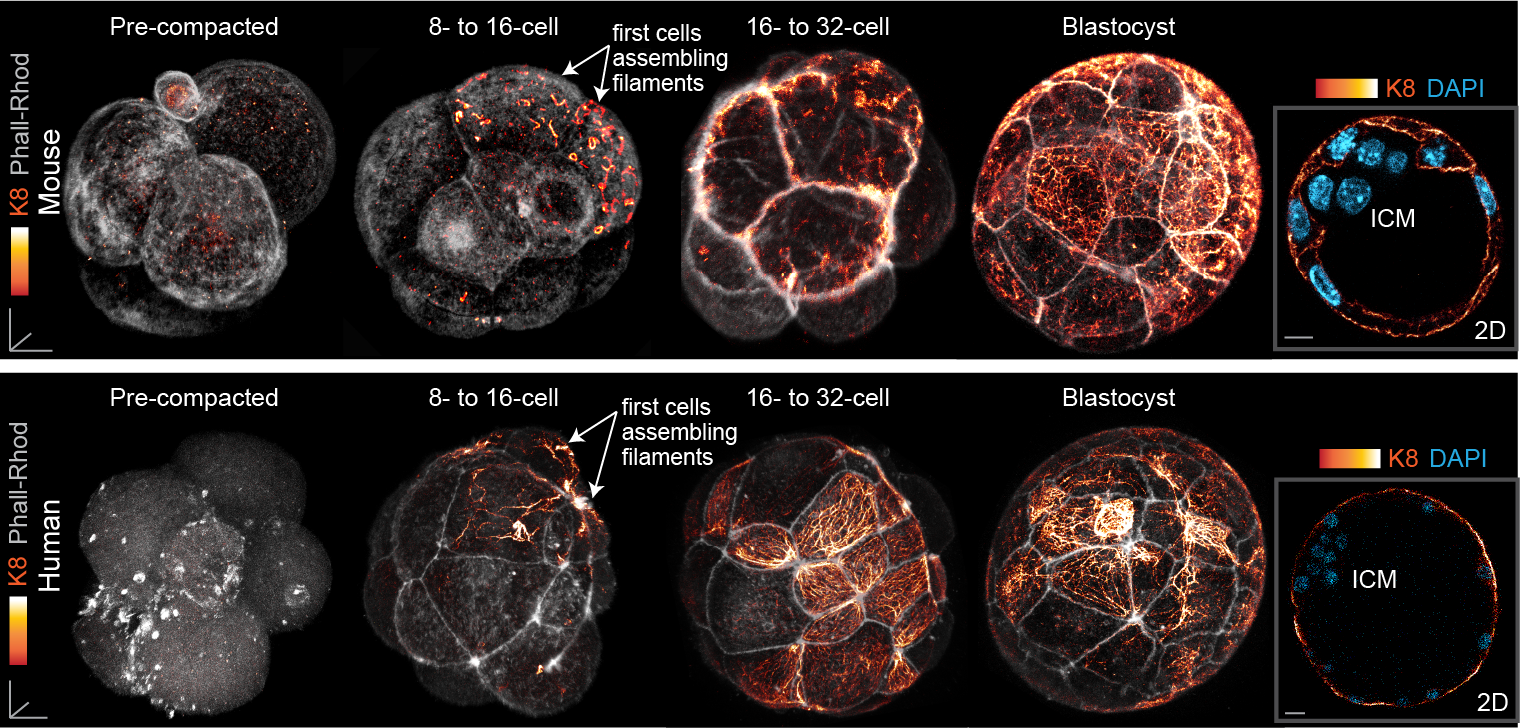
Finally, our study also led us to uncover a surprising pattern of keratin expression during preimplantation development: Keratins assemble a dense filament network extending throughout all cells of the blastocyst trophectoderm, but instead display a salt-and-pepper pattern during earlier stages (Fig. 3). In both the mouse and human embryo, the first filaments form in a subset of cells of the 8- to 16-cell embryo, and the proportion of keratin-assembling cells increases over time. Importantly, the heterogenous keratin expression stands in stark contrast to actin filaments and microtubules, which both do not differ significantly in expression from cell to cell. This initial heterogenous expression of keratins at the 8-cell stage can be further attributed to cell-cell differences in the levels of the BAF chromatin remodelling complex within the 4-cell embryo, with manipulations of BAF levels sufficient to trigger changes in keratin expression patterns.
Fig. 3. Keratin filaments are heterogeneously expressed in the early embryo, beginning first in a subset of cells of the 8- to 16-cell mouse and human embryo. By the blastocyst stage, all trophectoderm cells are covered with a dense keratin filament network, but inner cells remain devoid of filaments.
Together, these findings connect cellular heterogeneities within the early embryo to fate specification pathways at later stages via the regulation of keratin expression. Although keratins have long been utilized as markers of the trophectoderm, our work further identifies keratins as regulators of trophectoderm fate, elucidating one of the first functions for these filaments during early development. With keratins once again placed in the spotlight and more experimental tools at our disposal, our understanding of keratins in the early mammalian embryo is set to expand in the years to come.
Baribault, H., Price, J., Miyai, K., and Oshima, R.G. (1993). Mid-gestational lethality in mice lacking keratin 8. Genes & Development 7, 1191–1202.
Baribault, H., Penner, J., Iozzo, R.V., and Wilson-Heiner, M. (1994). Colorectal hyperplasia and inflammation in keratin 8-deficient FVB/N mice. Genes & Development 8, 2964–2973.
Chisholm, J.C., and Houliston, E. (1987). Cytokeratin filament assembly in the preimplantation mouse embryo. Development 101, 565–582.
Duprey, P., Morello, D., Vasseur, M., Babinet, C., Condamine, H., Brulet, P., and Jacob, F. (1985). Expression of the cytokeratin endo A gene during early mouse embryogenesis. Proceedings of the National Academy of Sciences of the United States of America 82, 8535–8539.
Emerson, J.A. (1988). Disruption of the cytokeratin filament network in the preimplantation mouse embryo. Development 104, 219–234.
Jackson, B.W., Grund, C., Schmid, E., Bürki, K., Franke, W.W., and Illmensee, K. (1980). Formation of Cytoskeletal Elements During Mouse Embryogenesis: Intermediate Filaments of the Cytokeratin Type and Desmosomes in Preimplantation Embryos. Differentiation 17, 161–179.
Kirfel, J., Magin, T.M., and REICHELT, J. (2003). Keratins: a structural scaffold with emerging functions. Cellular and Molecular Life Sciences (CMLS) 60, 56–71.
Magin, T.M., Schröder, R., Leitgeb, S., Wanninger, F., Zatloukal, K., Grund, C., and Melton, D.W. (1998). Lessons from Keratin 18 Knockout Mice: Formation of Novel Keratin Filaments, Secondary Loss of Keratin 7 and Accumulation of Liver-specific Keratin 8-Positive Aggregates. J Cell Biol 140, 1441–1451.
Oshima, R.G., Howe, W.E., Klier, G., Adamson, E.D., and Shevinsky, L.H. (1983). Intermediate Filament Protein Synthesis in Preimplantation Murine Embryos. Developmental Biology 99, 447– 455.
Pan, X., Hobbs, R.P., and Coulombe, P.A. (2013). The expanding significance of keratin intermediate filaments in normal and diseased epithelia. Current Opinion in Cell Biology 25, 47–56.
Paulin, D., Babinet, C., Weber, K., and Osborn, M. (1980). Antibodies as probes of cellular differentiation and cytoskeletal organization in the mouse blastocyst. Experimental Cell Research 130, 297–304.
White, M.D., Zenker, J., Bissiere, S., and Plachta, N. (2018). Instructions for Assembling the Early Mammalian Embryo. Developmental Cell 45, 667–679.
Following the initial discovery of the homeobox in the 1980s in invertebrates and then vertebrates, it became quickly clear that homeobox genes come in two flavors – that of the Antennapedia-like HOX cluster genes and that of the many more non-clustered genes with diverse sequence and expression features (Gehring, 1998). One theme that became evident through expression and mutant analysis in a variety of organisms was the selective expression and function of homeobox genes within the nervous system (Gehring, 1998).
When I started to look for postdoctoral positions in the early 1990s, I was particularly intrigued by mutant phenotypes of several fly and worm homeobox genes (Blochlinger et al., 1988; Doe et al., 1988; Finney and Ruvkun, 1990; Way and Chalfie, 1988), but also by the work of the late Tom Jessell, who proposed a LIM homeobox code in the vertebrate spinal cord (Tsuchida et al., 1994). The simplicity and well-characterized nature of the C. elegans nervous system, as well as its genetic amenability was very appealing to me and, in 1996, I decided to join Gary Ruvkun’s lab. Gary’s lab had not only characterized one of the first C. elegans homeobox genes, unc-86 (Finney and Ruvkun, 1990; Finney et al., 1988); Thomas Bügrlin in Gary’s lab had also used library screening with degenerate probes, a method that now, in the post-genome era, seems quite archaic, to discover the abundance of homeobox genes in this simple organism (Burglin et al., 1989).
In Gary’s lab, I set out to study the expression and function of the LIM homeobox subfamily, which were discovered initially by Marty Chalfie (Way and Chalfie, 1988) and implicated further in neuronal identity specification by Tom Jessell’s lab (Tsuchida et al., 1994). Using emerging GFP reporter technology (Chalfie et al., 1994) and mutant analysis, I determined what turned out to be mostly incomplete expression patterns (owing to the shortcomings of “classic” reporter genes which often just contained fractions of their surrounding gene regulatory regions) and mutant phenotypes that could only be very superficially analyzed (owing to a shortage of markers that allowed for a more in-depth analysis of mutant phenotypes)(Hobert et al., 1998; Hobert et al., 1997; Hobert et al., 1999).
After starting my own lab at Columbia University in 1999, a string of students and postdocs (Zeynep Altun, Adam Wenick, Ephraim Tsalik, Feifan Zhang, Pat Gordon, Vincent Bertrand, Maria Doitsidou, Nuria Flames, Rich Poole, Paschalis Kratsios, Marie Gendrel, Esther Serrano-Saiz, Laura Pereira, among others) continued to work on a small number of specific homeobox genes, digging much deeper into what these genes did in the nervous system. One theme that continued to emerge throughout this analysis was that not only the classic unc-86 and mec-3 genes, studied in impressive depth by Marty Chalfie over the years (Chalfie, 1995), but other homeobox genes as well had a remarkably broad effect on the differentiation of specific neuron types. Rather than regulating only some subset of specific identity features in a neuron, several homeobox genes fulfilled a “master regulatory” role in controlling most, if not all, known identity features of a neuron, through direct initiation and maintenance of terminal differentiation gene batteries. This led me to propose the concept of “terminal selectors” of neuronal identity, a term extended from the Drosophila field where “selector genes” were coined as genes that act earlier in development to specify the identity of developing fields and tissues (Hobert, 2016).
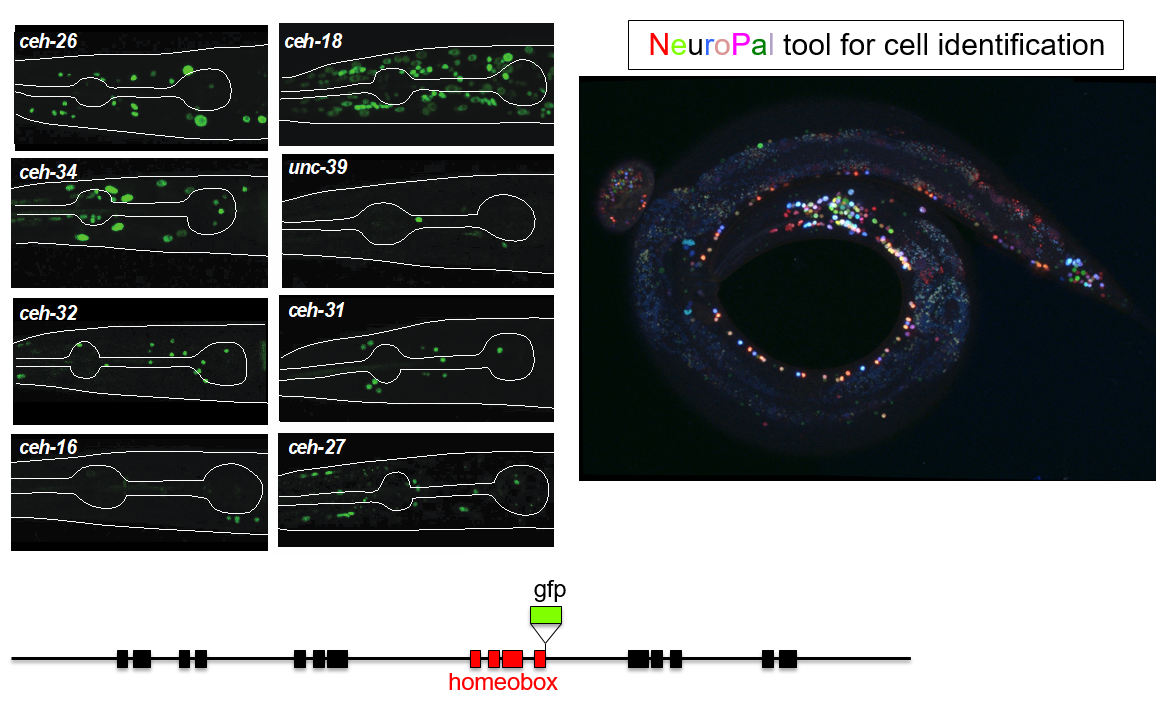
This trajectory finally led to the work of Molly Reilly, a graduate student in my lab, who recently set out to achieve the ambitious goal of describing the expression patterns of the entire homeobox gene family across the entire C. elegans nervous system (Reilly et al., 2020). This tremendous leap forward was, as so often is the case, enabled by novel technology. First, gene expression patterns, or even better, protein expression patterns, can now be much more reliably identified by not just extracting some arbitrary small regulatory region adjacent to your gene of interests to drive a reporter gene. Rather, bacterial recombineering technology enables the reporter tagging of genes in the context of very large genomic intervals containing many genes up- and downstream of the gene of interest (Tursun et al., 2009). Moreover, CRISPR/Cas9 technology even allowed for reporter tagging of an entire locus in the endogenous context (Dickinson et al., 2013). But even with good reagents at hand, identifying sites of expression of a reporter gene across the entire nervous system has traditionally not been a small feat because neurons in C. elegans are tightly packed and their position can be locally variable. Here is where Eviatar Yemini, a postdoc in my lab, came in to solve the long-standing problem of neuronal cell identification. Using multiple distinct fluorophores (excluding GFP), Eviatar built a multicolor landmark strain, NeuroPAL, which unlike Brainbow-style technology, assigned neurons a strictly deterministic color code (Yemini et al., 2019). Crossing NeuroPAL with a GFP reporter strain enables unambiguous identification for the sites of gene expression, anywhere in the nervous system (Figure 1).
Figure 1: Examples of homeobox reporter gene expression patterns. The NeuroPAL transgene (left panel) was crosses to these reporters to unambiguously identify sites of homeobox gene expressions. Images courtesy of Molly Reilly and Ev Yemini.
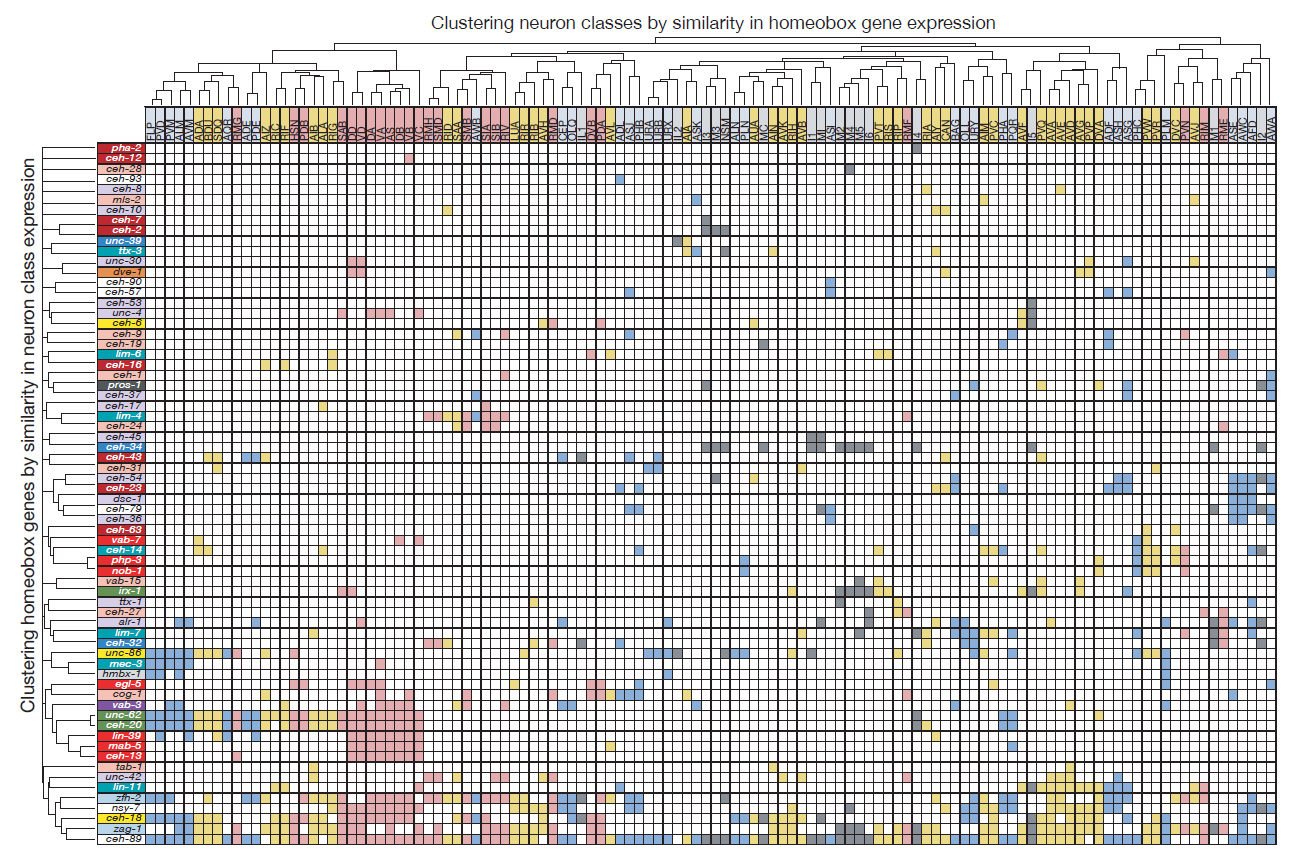
Molly exploited these technological advances to (a) tag all but one of the 102 homeobox genes of C. elegans with a fluorescent reporter and (b) identify their sites of expression throughout the entire nervous system. What she found was something I could barely have dreamed of when starting my postdoc in Gary’s lab: Most of the conserved homeobox genes are not only sparsely expressed throughout the nervous system of the worm, but each of the 118 different neuron classes displayed a unique combination of homeobox genes (Figure 2).
Figure 2: Homeobox codes. Shown are all the homeobox gene expression patterns that contribute to neuron class specific expression. Homeobox genes are on top, neuron classes on the left. Reproduced from Reilly et al., 2020.
Homeobox genes are thus a comprehensive “descriptor” of neuronal diversity throughout an entire nervous system – a homeobox code for all neurons! Furthermore, the mapping of these homeobox genes led another graduate student, Cyril Cros, to find that neurons previously not known to express or require a homeobox gene, do indeed also require a homeobox gene for their identity specification (Reilly et al., 2020).
This is not the end of the road. The lab remains motivated to test whether indeed every single C. elegans neurons not only expresses, but requires a homeobox gene for their identity specification. Moreover, it remains little explored to what extent we can reprogram the identity of neurons by respecifying their homeobox codes. I am looking forward to see whether work in other systems with more complex brains will also uncover the broad employment of homeobox codes. Recent transcriptome analysis in restricted parts of the flies and mice CNS indeed provides tantalizing hints for similar specificity and selectivity of homeobox gene expression in more complex nervous systems (Allen et al., 2020; Davis et al., 2020; Sugino et al., 2019).
Mechanism of cell polarisation and first lineage segregation in the human embryo
Meng Zhu, Marta N. Shahbazi, Angel Martin, Chuanxin Zhang, Berna Sozen, Mate Borsos, Rachel S. Mandelbaum, Richard J. Paulson, Matteo A. Mole, Marga Esbert, Richard T. Scott, Alison Campbell, Simon Fishel, Viviana Gradinaru, Han Zhao, Keliang Wu, Zijiang Chen, Emre Seli, Maria J. de los Santos, Magdalena Zernicka-Goetz
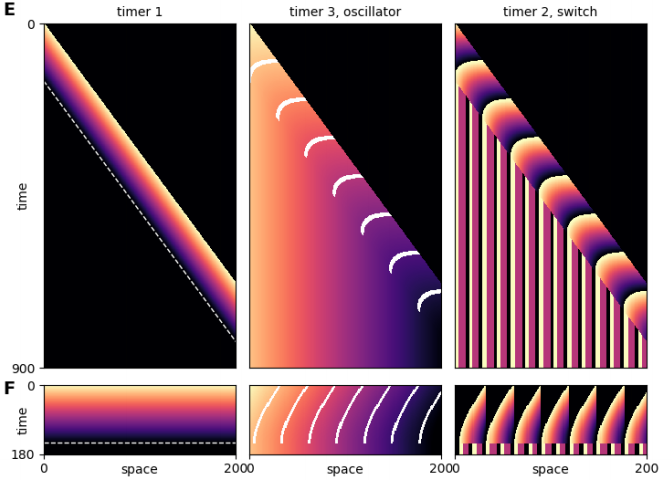
Hedgehog signaling activates a heterochronic gene regulatory network to control differentiation timing across lineages
Megan Rowton, Carlos Perez-Cervantes, Ariel Rydeen, Suzy Hur, Jessica Jacobs-Li, Nikita Deng, Emery Lu, Alexander Guzzetta, Jeffrey D. Steimle, Andrew Hoffmann, Sonja Lazarevic, Xinan Holly Yang, Chul Kim, Shuhan Yu, Heather Eckart, Sabrina Iddir, Mervenaz Koska, Erika Hanson, Sunny Sun-Kin Chan, Daniel J. Garry, Michael Kyba, Anindita Basu, Kohta Ikegami, Sebastian Pott, Ivan P. Moskowitz
Proneural genes define ground state rules to regulate neurogenic patterning and cortical folding
Sisu Han, Grey A Wilkinson, Satoshi Okawa, Lata Adnani, Rajiv Dixit, Imrul Faisal, Matthew Brooks, Veronique Cortay, Vorapin Chinchalongporn, Dawn Zinyk, Saiqun Li, Jinghua Gao, Faizan Malik, Yacine Touahri, Vladimir Espinosa Angarica, Ana-Maria Oproescu, Eko Raharjo, Yaroslav Ilnytskyy, Jung-Woong Kim, Wei Wu, Waleed Rahmani, Igor Kovalchuk, Jennifer Ai-wen Chan, Deborah Kurrasch, Diogo S. Castro, Colette Dehay, Anand Swaroop, Jeff Biernaskie, Antonio del Sol, Carol Schuurmans
Fine-tuning of Epithelial EGFR signals Supports Coordinated Mammary Gland Development
Alexandr Samocha, Hanna M. Doh, Vaishnavi Sitarama, Quy H. Nguyen, Oghenekevwe Gbenedio, Joshua D. Rudolf, Walter L. Eckalbar, Andrea J. Barczak, Yi Miao, K. Christopher Garcia, Devon Lawson, Zena Werb, Kai Kessenbrock, Philippe Depeille, Jeroen P. Roose
Tissue topography steers migrating Drosophila border cells
Wei Dai, Xiaoran Guo, Yuansheng Cao, James A. Mondo, Joseph P. Campanale, Brandon J. Montell, Haley Burrous, Sebastian Streichan, Nir Gov, Wouter Jan Rappel, Denise J. Montell
A Human Multi-Lineage Hepatic Organoid Model for Liver Fibrosis
Yuan Guan, Annika Enejder, Meiyue Wang, Zhuoqing Fang, Lu Cui, Shih-Yu Chen, Jingxiao Wang, Yalun Tan, Manhong Wu, Xinyu Chen, Patrik K. Johansson, Issra Osman, Koshi Kunimoto, Pierre Russo, Sarah C. Heilshorn, Gary Peltz
Secondary ossification center induces and protects growth plate structure
Meng Xie, Pavel Gol’din, Anna Nele Herdina, Jordi Estefa, Ekaterina V Medvedeva, Lei Li, Phillip T Newton, Svetlana Kotova, Boris Shavkuta, Aditya Saxena, Lauren T Shumate, Brian Metscher, Karl Großschmidt, Shigeki Nishimori, Anastasia Akovantseva, Anna P Usanova, Anastasiia D Kurenkova, Anoop Kumar, Irene Linares Arregui, Paul Tafforeau, Kaj Fried, Mattias Carlström, Andras Simon, Christian Gasser, Henry M Kronenberg, Murat Bastepe, Kimberly L. Cooper, Peter Timashev, Sophie Sanchez, Igor Adameyko, Anders Eriksson, Andrei S Chagin
Visualizing the metazoan proliferation-terminal differentiation decision in vivo
Rebecca C. Adikes, Abraham Q. Kohrman, Michael A. Q. Martinez, Nicholas J. Palmisano, Jayson J. Smith, Taylor N. Medwig-Kinney, Mingwei Min, Maria D. Sallee, Ononnah B. Ahmed, Nuri Kim, Simeiyun Liu, Robert D. Morabito, Nicholas Weeks, Qinyun Zhao, Wan Zhang, Jessica L. Feldman, Michalis Barkoulas, Ariel M. Pani, Sabrina L. Spencer, Benjamin L. Martin, David Q. Matus
Single-cell analysis of chromatin silencing programs in developmental and tumor progression
Steven J. Wu, View ORCID ProfileScott N. Furlan, Anca B. Mihalas, Hatice Kaya-Okur, View ORCID ProfileAbdullah H. Feroze, Samuel N. Emerson, View ORCID ProfileYe Zheng, Kalee Carson, Patrick J. Cimino, C. Dirk Keene, View ORCID ProfileEric C. Holland, View ORCID ProfileJay F. Sarthy, View ORCID ProfileRaphael Gottardo, View ORCID ProfileKami Ahmad, View ORCID ProfileSteven Henikoff, View ORCID ProfileAnoop P. Patel
Automated cell tracking using StarDist and TrackMate
Elnaz Fazeli, Nathan H. Roy, Gautier Follain, Romain F. Laine, Lucas von Chamier, Pekka E. Hänninen, John E. Eriksson, Jean-Yves Tinevez, Guillaume Jacquemet
Research practice & education
Preprinting the COVID-19 pandemic
Nicholas Fraser, Liam Brierley, Gautam Dey, Jessica K Polka, Máté Pálfy, Federico Nanni, Jonathon Alexis Coates
Measuring effects of trainee professional development on research productivity: A cross-institutional meta-analysis
Patrick D. Brandt, Susi Sturzenegger Varvayanis, Tracey Baas, Amanda F. Bolgioni, Janet Alder, Kimberly A. Petrie, Isabel Dominguez, Abigail M. Brown, C. Abigail Stayart, Harinder Singh, Audra Van Wart, Christine S. Chow, Ambika Mathur, Barbara M. Schreiber, David A. Fruman, Brent Bowden, Chris E. Holmquist, Daniel Arneman, Joshua D. Hall, Linda E. Hyman, Kathleen L. Gould, Roger Chalkley, Patrick J. Brennwald, Rebekah L. Layton
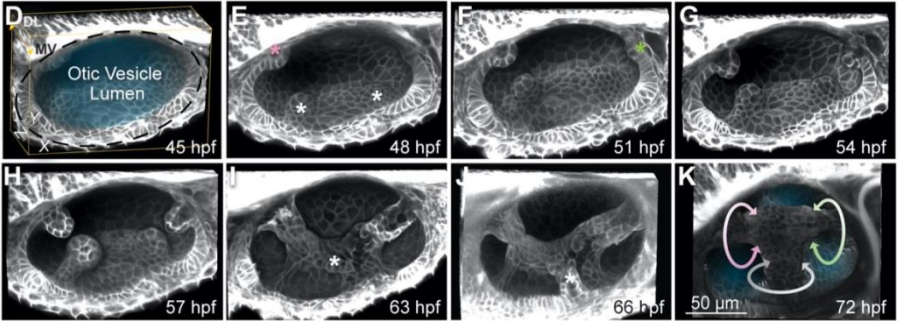
Optic cup development involves a series of intricate cell and tissue movements, and cells’ interaction with the extracellular matrix (ECM) is known to play an important role. However, the details of how ECM components work in eye development, and where they come from, is still poorly understood, and is the subject of a new Development paper that takes advantage of live imaging in zebrafish embryos. We caught up with first author Chase Bryan and his supervisor Kristen Kwan, Assistant Professor in the Department of Human Genetics at the University of Utah, Salt Lake City, to find out more about the story.
Chase (L) and Kristen (R)
Kristen, can you give us your scientific biography and the questions your lab is trying to answer?
KK Thanks for asking! I am a cell and developmental biologist. I got my start as a biochemist studying membrane trafficking as an undergraduate in Suzanne Pfeffer’s lab at Stanford University. I worked with Marc Kirschner during my PhD, and it was during that time that I began thinking about morphogenesis; I worked toward understanding how developmental signals are integrated with the cytoskeleton and cell adhesion during Xenopus development. Marc gave me a lot of freedom to develop these ideas, and since then I’ve been fascinated by the problem. Knowing that I wanted to do live imaging, I went on to do a postdoc with Chi-Bin Chien, where I began working on eye morphogenesis in zebrafish. Chi-Bin was extremely supportive and helped me start to develop computational approaches to address this problem. My lab is currently working to understand the cellular and molecular mechanisms governing eye morphogenesis. When, where and how do cells move? How is the tissue organized? How does the embryo construct three-dimensional organs in a precise and stereotyped manner? We hope to answer questions like these by combining live imaging, computational methods, genetics and cell biology.
Chase, how did you come to work with Kristen and what drives your research today?
CB I met Kristen briefly prior to starting graduate school at the University of Utah – I was working as a lab technician at the time, and the postdoc I was working with asked if I wanted to go see his friend’s (Kristen’s) job interview seminar. When I saw the movies of zebrafish optic cup development she made during her postdoc and heard the pitch she had for her science (something like ‘you can understand so much of biology simply by watching it happen’), I knew I wanted to work with her and have her teach me those techniques. That same idea drives the work I am doing now as a postdoc.
What did we know about the ECM’s role in optic cup morphogenesis before your work?
CB & KK We know surprisingly little about the function of ECM molecules! Research over many decades has described the presence of ECM proteins around the developing optic cup in many different organisms, but much less has been discovered about ECM function. Work from other groups has demonstrated that the ECM protein fibronectin is important to establish the lens, as is laminin-1. Different subunits of laminin-1 have also been shown to regulate optic cup shape, cell polarity and retinal differentiation, but beyond these proteins not much is known about the functional role of other ECM components.
Can you give us the key results of the paper in a paragraph?
CB & KK Mesenchymal cells have been observed surrounding the developing eye for decades, and studies in mouse had demonstrated that mutants with disruptions to the periocular mesenchyme display optic cup morphology defects, but a specific role of either the mesodermal mesenchyme or the migratory neural crest have not been well established. In this research, we focused on the neural crest, as we had genetic tools ready at hand to try and parse out the role of those cells in optic cup morphogenesis. We found that neural crest mutants in zebrafish displayed optic cup defects, and observed that neural crest cells migrate around the developing eye throughout optic cup morphogenesis. We then found that neural crest helps establish the basement membrane that surrounds the retinal pigment epithelium. These neural crest cells express the ECM protein nidogen, and by disrupting nidogen function we found that this neural crest-derived nidogen is necessary for proper optic cup morphogenesis.
Why do you think optic vesicle cells move faster when the basement membrane is disrupted?
CB & KK We propose in our model that the basement membrane serves as a molecular handbrake for the movement of optic vesicle cells. The optic vesicle develops as a bilaminar epithelial tissue, so movement in one part of the epithelium could push or pull other parts of the tissue forward or backward, like a conveyor belt. The basement membrane could serve as an adhesive layer for the epithelia to stick to, and could thereby regulate the speed at which individual cells or the sheet as a whole get moved along. Without the basement membrane in place to adhere to, those cells could lose their footing, so to speak, and keep getting pushed or pulled along faster than they do in wild-type conditions.
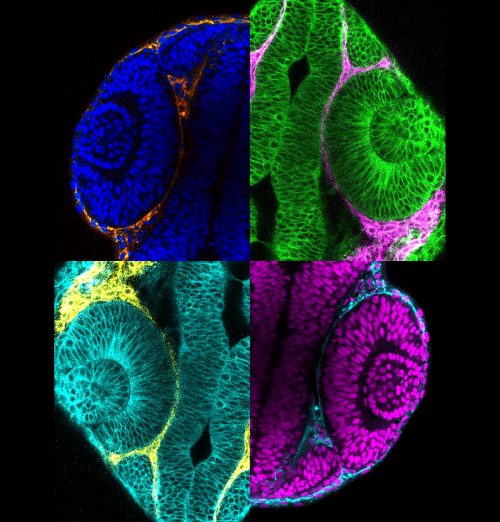
Collage of pseudocoloured micrographs of 24 h post-fertilization zebrafish optic cups surrounded by periocular neural crest cells.
And do you think all of the defects you observe result from problems with cell movements, or might other mechanical or signalling aspects be affected?
CB & KK Other mechanical or signalling aspects could certainly be affected when neural crest or basement membrane assembly get disrupted. The ECM has many known roles in regulating movement and presentation of signalling molecules, only a couple of which we have directly tested. In terms of mechanical aspects, integrin signalling is one obvious molecular link between the ECM and the cells that adhere to it, which could affect the cytoskeleton and in turn regulate epithelial morphogenesis. There are also a lot of unexplored mechanical and biophysical aspects of morphogenesis, and the ECM may play into many other pathways, such as Hippo or tension receptors.
When doing the research, did you have any particular result or eureka moment that has stuck with you?
CB I’m lucky because this project was full of satisfying little events. Some of the most memorable moments of my graduate work came from this project: taking a time-lapse image where the optic cup stayed in focus throughout the night and getting to watch the neural crest migrate around the eye, or looking at beautiful electron micrographs after spending an entire weekend prepping samples for electron microscopy. Perhaps the biggest moment like this came after I’d spent months engineering and raising the nidogen transgenics. To engineer the transgenes, inject the fish, raise multiple generations, and finally get to perform the heat-shock experiments and find that the transgenes worked just like I’d predicted was immensely gratifying.
“Some of the most memorable moments of my graduate work came from this project”
And what about the flipside: any moments of frustration or despair?
CB There was definitely some frustration working with a double mutant, and even more so when we started adding in transgenes. Even with zebrafish where you can have hundreds of embryos to work with at any given time, you can only work with a handful before they develop beyond the time point you’re trying to study. We had many experiments where Mendelian genetics worked against us and we didn’t get more than one or two embryos with the correct genotype.
So what next for you after this paper – I hear you’ve moved cross country?
CB That’s right, I recently started a postdoc with Marty Cohn at the University of Florida. I’m still keenly interested in the cell biology underlying morphogenesis – I’ve been developing a mouse organ culture system and am using the live-imaging techniques I learned from Kristen to study the formation of the mammalian urethra and to understand how normal development is altered in a condition called hypospadias.
Where will this work take the Kwan lab?
KK I am truly excited about where this work has led us: Chase’s work indicates that building the basement membrane is a collaborative endeavour between different tissues. Moving forward, we are extremely interested in identifying other ECM molecules provided by extraocular sources. Our preliminary data suggest that there are multiple cell types providing many different ECM molecules to the developing eye. We are excited to determine how these function in an integrated manner to support proper eye development.
Finally, let’s move outside the lab – what do you like to do in your spare time?
CB I enjoy figuring out how things work, and that expands beyond biology – before I was a cell biologist, I spent my free time rebuilding cars and motorcycles. I’m still an avid motorcyclist, but since moving to Florida I’ve also been taking advantage of the sun to get more into bicycling and triathlon training.
The Southwest Zebrafish Meeting 2020 (SWZM20) took place as an online-only meeting organized by the Scholpp lab at the Living Systems Institute, University of Exeter UK, on September 11th 2020. This meeting brought together 90 scientists, mostly from Southwest of the UK, who work with the zebrafish Danio rerio and was supported by a Scientific Meeting grant from the Company of Biologists and from the companies Tecniplast and DanioLab. We provide the readers who might have missed this event with a glimpse of the recent scientific advancements and experimental approaches applied by research groups using fish as a model to understand molecular and cellular mechanisms in development, to explore its role as an in vivo reporter in environmental sciences, and to elucidate common principles in organ regeneration.
To kick-off the SWZM20, Phil Ingham (NTU Singapore) introduced the International Zebrafish Society (IZFS). Then, the first session started with a lecture from Isaac Bianco (University College London), on the usage of zebrafish to understand how neural circuits control complex behaviour in zebrafish. One of their most complex visually guided behaviours is hunting, which begins from only 5 days post-fertilisation. Isaac and his team showed how the larval brain processes visual inputs to identify prey. The zebrafish visualizes specific features of the object, which are extracted and help to identify potential prey leading to the initiation of a hunting routine. During prey tracking, the zebrafish larvae coordinate a directed swim behaviour including turns towards the target. His team could show that that recent experience modulates the core output. His talk was followed by a further talk on fish behaviour from Min-Kyeung Choi (Ryu lab, LSI, Exeter) on the consequences of early life stress on social behaviour. These talks were followed by a session on signalling. Georgina McDonald (Hammond lab, University of Bristol) reported about the function of SMAD9 signalling in developing bones, Chengting Zhang (Scholpp lab, LSI Exeter) and Rachel Moore (Clarke lab, King’s College London) highlighted the importance of cell protrusions in signal transport and signal reception. Finally, Robert Kelsh (Department of Biology and Biochemistry, University of Bath) elucidated on the formation of the stripe pattern in zebrafish by a lattice-based mathematical model helping him to identify the crucial interactions between the different pigment cells in establishing of the distinguished pattern of zebrafish.
The SWZM20 used an online virtual bulletin board, where delegates could listen to talks, discuss poster presentations, engage with sponsors, collaborate and meet with colleagues, and enjoy their snacks in the Fish Café.
The behaviour/cell session was followed by the poster session. PhD students and postdocs from our zebrafish community presented and discussed their work in break-out rooms. After the lunch break, we discussed zebrafish as a model for ecotoxicology. Rebecca Boreham (Tyler lab, University of Exeter) and Sophie Cook (Lloyd-Evans lab, University of Cardiff) presented their data on the usage of transgenic zebrafish larvae as in vivo sensors of chemical-induced stress and the toxicity of iron oxide nanoparticles. This session was closed by a lecture from Charles Tyler (School of Biosciences, University of Exeter). In his work, transgenic zebrafish lines are developed that are sensitive to endocrine disruptors such as oestrogen-like chemicals. The transgenic zebrafish lines allow his team to identify where different chemicals interact in the body and in real-time. This is a very powerful tool to investigate the potential for wider health impacts of exposure to environmental oestrogens. Members of his team also work on other chemical contaminants of environmental and human health concern including pesticides and pharmaceuticals and how the zebrafish can help us to detect them and learn more about accumulation in specific organs. This was followed by a talk from Gregory Paull (Aquatic Resource Facility Manager, University of Exeter) on the important balance of husbandry with scientific research.
Delegates that participated in the Southwest Zebrafish Meeting 2020 (SWZM20) organized by the Living Systems Institute, University of Exeter UK, 11th Sep 2020.
In the final session of the day, the importance of zebrafish research in elucidating general principles in organ regeneration was discussed. This session started with four short talks from Daniel Wehner (MPI Erlangen, Germany) on axon regeneration; Paco Lopez-Cuevas (Martin lab, University of Bristol) on reprogramming macrophages and neutrophils; Noemie Hamilton (University of Sheffield) on microglial function and its contribution to the pathology of a childhood white matter disorder; and Rebecca Ryan (Richardson lab, University of Bristol) studying the role of Osteopontin in zebrafish cardiac regeneration. The session was closed by a lecture from Catherina Becker (Centre of Discovery Brain Sciences, University of Edinburgh) on investigating the cellular mechanism underlying regeneration of the zebrafish spinal cord. In her talk, she was focussing on the active spinal cord progenitor cells around the lesion and elucidated lesion-induced neurogenesis.
To end this wonderful day, the best posters and talks received prizes according to a qualified majority voting. Two delegates won prizes for their fantastic talks. Georgina McDonald, from the University of Bristol, gave an impressive talk that showed us how SMAD9 is regulated and expressed in zebrafish skeletal elements. Rachel Moore, from KCL, explained how actin-based protrusions lead microtubules during axon initiation in spinal neurons in vivo. A further two delegates won prizes for their informative posters. Aaron Scott, from the University of Bristol, displayed a colourful story on in vivo characterisation of endogenous and cardiovascular extracellular vesicles in zebrafish. Lastly, Yosuke Ono, from the University of Exeter, created an enlightening poster on post-embryonic development and growth of slow-twitch muscle fibres in zebrafish. All talks and posters presented were deserving of awards, but these were particularly exceptional from a scientific and exhibitive perspective.
The powerful imaging techniques, the emerging tools to study complex vertebrate behaviour, the possibility to study in vivo cell biology within a living organism, and the usage of zebrafish in analysing the effect of chemicals on an organism are only a few of the many reasons why zebrafish is and will remain an excellent research model in the future. And another reason to work with zebrafish became obvious during this day: Working with zebrafish makes you part of a fantastic, noble and lively community. The SWZM20 was an outstanding celebration of this wonderful fellowship. The SWZM20 with delegates from diverse backgrounds further underscored the need for close interaction in the zebrafish research field. Despite some local collaborations in the Southwest of the UK, a stronger network still has to be developed between the four main scientific centres of Exeter, Bristol, Bath and Cardiff. We thereby hope that the SWZM20 could serve as a springboard for even more future interactions from basic biology to translational research.
And this is also a reason why we are looking forward to meeting again next year for the SWZM21 in Bath!

 (No Ratings Yet)
(No Ratings Yet)
 (3 votes)
(3 votes)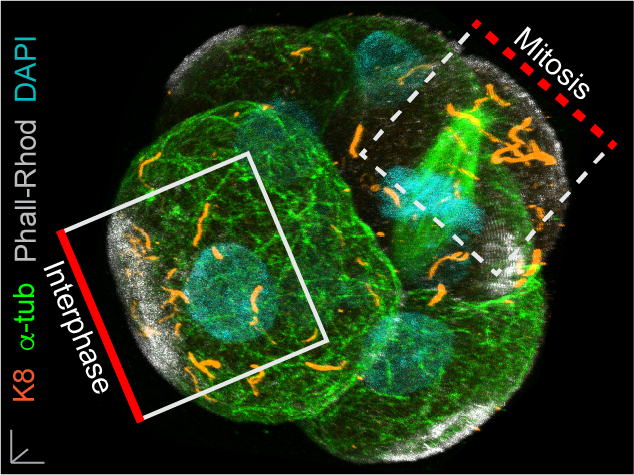









 Steffen, Lucy,
Steffen, Lucy,